.png)

The Cost of Maintaining an On-Premises Archiving Solution
Whether you’ve already moved to the cloud and are still maintaining your on-premises Veritas Enterprise Vault email archive or have already moved and are leaving your legacy archive in place for ongoing journaling, there’s a high cost associated with your decision. Simply put, by maintaining on-premises computing and storage infrastructure, you’re investing increasing capital in an aging platform that doesn’t meet your current requirements and won’t in the future.
Paying the Price for On-Premise Archives Like Veritas/Enterprise Vault
A recent Osterman Research white paper provided the following findings…
- Enterprise Vault is a capable on-premise platform for archiving various types of content, including email, SharePoint data, file shares, etc.
- Keeping your on-premises EV archiving solution active while you are moving the rest of your data center to the cloud does not fit with your digital transformation strategy.
- Enterprise Vault is relatively expensive compared to many alternatives, particularly those in the cloud.
Enterprise Vault itself only will cost more every year as the diagrams below show. Draining funds through software and hardware support, labor and power demands, the increasing total cost of ownership only further makes the case for a cloud-based archiving solution.
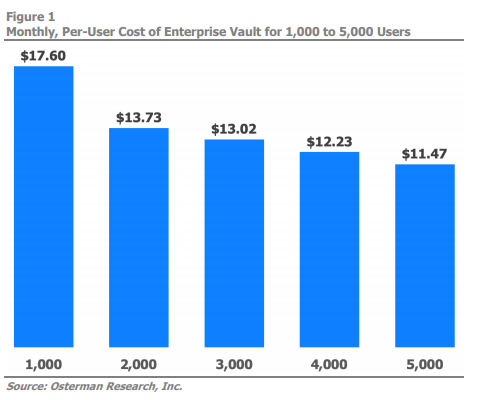
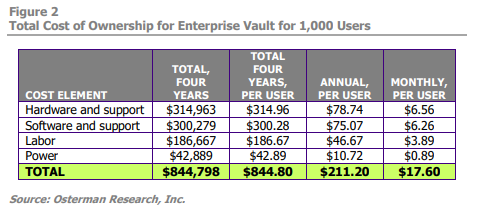
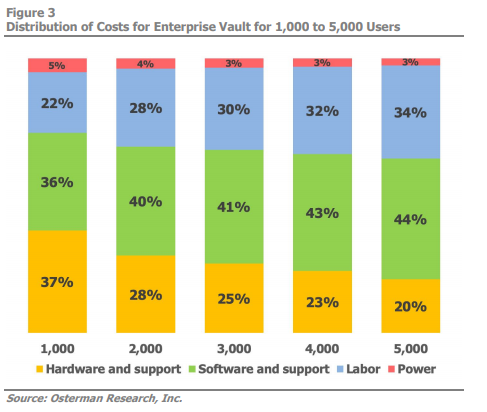
Option 1: Second-Rate SaaS Archiving
The Halfway House – Why Migrating From Enterprise Vault to Enterprise Vault.cloud Isn’t the Ideal Solution
SaaS archiving platforms have been around for a while now, with legacy vendors like Veritas (as well as others like Smarsh, Mimecast and GlobalRelay) making use of the SaaS model to deliver one-size-fits-all archiving solutions. In the early days of SaaS, cloud solutions such as these had some major selling points and they were the only cloud solutions available. They helped businesses to do away with ongoing on-premises infrastructure costs in favor of a convenient subscription service that required little input on their part. The problem is, they weren’t designed to be flexible or compatible with the true, hyperscale cloud requirements of today.
 With “agility” and “flexibility” key buzzwords in technology over the last few years, this obvious limitation quickly highlighted the apparent problem. As the world rapidly changes, especially in relation to technology and data security, SaaS-based archives aren’t designed or equipped to cope with shifting regulations and constantly emerging security threats, or the need for businesses to scale up and down based on business requirements, as the hyperscale cloud is.
With “agility” and “flexibility” key buzzwords in technology over the last few years, this obvious limitation quickly highlighted the apparent problem. As the world rapidly changes, especially in relation to technology and data security, SaaS-based archives aren’t designed or equipped to cope with shifting regulations and constantly emerging security threats, or the need for businesses to scale up and down based on business requirements, as the hyperscale cloud is.
While SaaS solutions might once have been the easiest or only way to go, their static feature sets and one-size-fits-all design restrictions now limit security, access, accountability, and direct control over your data.
Most SaaS-based archiving vendors will tell you they offer the best turn-key cloud archiving platform but, in reality, they only introduce the same issues you experience with legacy on-premises infrastructure, such as the lack of an easy way to harness analytics, Machine Learning, and AI. In other words, the SaaS “lowest-common-denominator” design and architecture cannot meet today's needs.
Sharing Your Cloud with Others
Many SaaS issues stem from a basic drawback of the model – the fact that most SaaS-based archiving vendors don’t own their own datacenters. Instead, they rent space in what’s called a multi-tenant cloud. In reality, the SaaS vendor is subletting their cloud tenancy to you and offer a single application hundreds of other companies.
Not only does this situation block the addition of new much-needed capabilities, but it also raises major security concerns. For instance, that fact that as a customer, you don’t have control of the encryption keys used to secure your data. This, coupled with a lack of control over the security processes and measures in place, means your company’s data could be inadvertently shared with all of the SaaS vendor’s other clients in the same multi-tenant cloud. That significantly increases the chances of unauthorized access i.e. viruses and ransomware, data corruption, or deletion. It also means the SaaS vendor can access your company’s sensitive data at any time or provide access to government agencies via secret subpoenas – without you ever knowing.
Vendor Data Ransom
While security is a major issue for all organizations, subscription costs and total cost of ownership is always a close second in importance. Most SaaS vendors will convert and store your company’s files in their own proprietary format that only their tools can access, essentially creating what amounts to a data prison. When you want to eventually move your data somewhere else, the vendor can charge you huge “reconversion fees” to move your data away from their service. On top of this data ransoming, the proprietary format also means you can’t use your data with AI or Machine Learning technology to provide content-based auto-classification and supervision for more accurate information management.
Before you consider a migration to Enterprise Vault.cloud, we suggest you check with the vendor:
- Do you have to pay a reconversion fee to extract your data out of your Enterprise Vault.cloud archive?
- What is the cost per GB for the extraction?
- Are there limitations on the amount of data I can search and extract per day?
Possible SaaS Archiving Issues:
- Limited or no control over your data’s geographic location – data sovereignty
- Little to no control over security capabilities
- Proprietary file formats that limit your ability to move your data without paying exorbitant fees - data ransoming
- Limited search and review options for audio, video and other non-email files
- Data analysis and eDiscovery functionality is limited to “lowest common denominator” vendor-provided tools
- No access to encryption keys used to encrypt your data
The Sad Truth of SaaS Security Stats
In a recent survey of global IT executives, including VPs, Directors, and members of the C-suite at major corporations, only 19% of those surveyed believed 75% or more of their SaaS vendors met all their security requirements. 70% stated they had been forced to make at least one security exception for a SaaS vendor. While many of these organizations are likely using popular SaaS products like Microsoft Office 365 and Salesforce, where the size and standing of the vendor might make the business more amenable to accepting a perceived lower risk, the clear takeaway is that many SaaS solutions don’t provide the security standards and flexibility modern organizations require.
 On the topic of encryption keys, an astounding 95% of respondents believed it was important to control their own encryption keys, and 81% were uncomfortable with their SaaS vendors controlling them. However, 74% of those surveyed said they did not control the encryption keys for the majority of their SaaS solutions. This is a worrying statistic and one that many organizations will have to take steps to reverse as regulations continue to tighten and the threat of cybercrime grows. To that end, 92% of executives said they would require more security customization in the future, with 63% of them planning to retire current SaaS applications that don’t provide them control over encryption key creation and management.
On the topic of encryption keys, an astounding 95% of respondents believed it was important to control their own encryption keys, and 81% were uncomfortable with their SaaS vendors controlling them. However, 74% of those surveyed said they did not control the encryption keys for the majority of their SaaS solutions. This is a worrying statistic and one that many organizations will have to take steps to reverse as regulations continue to tighten and the threat of cybercrime grows. To that end, 92% of executives said they would require more security customization in the future, with 63% of them planning to retire current SaaS applications that don’t provide them control over encryption key creation and management.
These statistics paint a clear picture of the security landscape and the risk that the one-size-fits-all approach of SaaS vendors introduces. As the trend for security customization continues and scrutiny over data access and handling increases, SaaS solutions will become increasingly less palatable for organizations’ risk mitigation efforts. Instead, more secure and customizable solutions will be a major focus.
Stunted Security: SaaS Vendors Don’t Let You Control…
- Physical data center security
- Encryption keys
- Custom compliance reporting
- Cloud-native directories
- Firewall and firewall rules
- Application security analysis
- Identity management/Access controls
- Threat detection

Download Now
Multi-Tenant SaaS vs Dedicated SaaS: what you need to know
All cloud archives are not created equal. There are major differences between archives deployed in a dedicated SaaS model versus a multi-tenant model that affect the security, accessibility and functionality of your archived data. This Technical Guide explores what you will need to consider in order to make an informed decision.

Technical Guide
Archive360 Archive Migration
A guide to Archive360's cloud-based approach to extract and migrate legacy data

Learn More
Archive360 Email Migration Software Product Highlights
Archive360 offers the most trusted archive and legacy data migration solution available - specifically designed for the Enterprise Vault archive. Fully integrated with the solution’s APIs for faster, more accurate data extractions, Archive360 extracts messages and attachments, including all metadata, directly from the archive, and maintains an item-level audit trail for compliance and legal reporting (chain of custody).



